1. redlock算法
不好意思,这个算法,我以前又他喵的没听过...
以下的文章是我摘抄网上的,底部有原文链接
如果你也没听过,我先简单总结下,再看这一段文字比较好理解
Redis节点一般有N个,假设5个
获取当前时间
client(客户端)挨个获取每个节点的锁,设置过期时间,防止在一个节点上耗费过多时间,如果获取不到,就转到下个节点
如果获取到了一半以上的节点的锁,而且锁的时间还没超出,那么表示成功获取了锁!
比如 ABCDE五个节点,成功获取了 ADE三个节点,锁的时间是10s(假设),获取锁消耗了4s,那么锁还有6s时间
释放锁的话 就是每个节点都走一遍..挨个释放锁!
另外,如果要看单点或者量不大的,可以看另外一篇.. 分布式锁
1.1. 前言
由于Redis集群数据同步是异步的,假设Master节点获取到锁后未完成数据同步情况下Master节点Crash,此时在新的Master节点依然可以获取到锁,这时多个客户端同时获取到了锁。
这个问题时这样的,假如Redis节点宕机了,那么所有客户端就都无法获得锁了,服务变得不可用。为了提高可用性,我们可以给这个Redis节点挂一个Slave,当Master节点不可用的时候,系统自动切换到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致failover过程中丧失锁的安全性。考虑下面的执行顺序:
- 客户端1从Master获取了锁
- Master宕机了,存储锁的key还没有来得及同步到Slave上
- Slave升级为Master
- 客户端2从新的Master获取到了对应同一个资源的锁
于是,客户端1和客户端2同时持有同一个资源的锁。锁的安全性被打破。
也就是说,前文的算法仅在单实例场景下是安全的,如果需要在集群环境实现分布式锁,可以采用Redlock算法。
1.2. Redlock算法描述
Redlock算法基于N个完全独立的Redis节点(通常情况下N可以设置为5)。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
- 获取当前时间(毫秒数)
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间,它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其他客户端持有。
- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2 + 1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validaty time),那么这时客户端才认为最终获取锁成功;否则认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取锁的Redis节点个数小于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis lua脚本)
当然,上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
1.2.1. 问题1
由于N个Redis节点中的大多数能正常功能就能保证Redlock正常工作,因此理论上它的可用性更高。单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响。具体的影响程度跟Redis对数据的持久化程度有关。
假设一共有5个Redis节点:A B C D E。设想发生了如下的事件序列:
- 客户端1成功锁住了A B C,获取锁成功(但D和E没有锁住)
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了
- 节点C重启后,客户端2锁住了C D E,获取锁成功
这样,客户端1和客户端2同时获得了锁(针对同一资源)
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。所以上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validty time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
1.2.2. 问题2
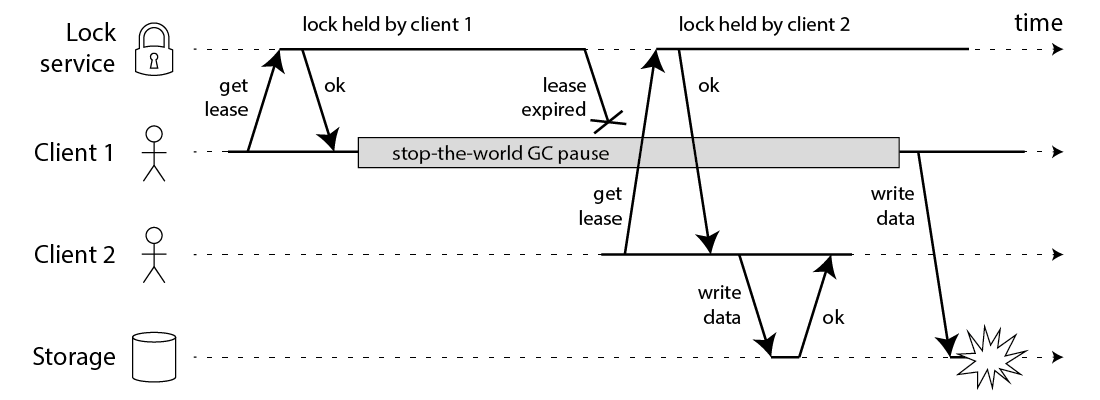
如上面的时序图所示,假设锁服务本身是没有问题的,它总是能保证任一时刻最多只有一个客户端获得锁。上图中出现的lease这个词可以暂且认为就等同于一个带有自动过期功能的锁。客户端1在获得锁之后发生了很长时间的GC pause,在此期间,它获得的锁过期了,而客户端2获得了锁。当客户端2获得了锁。当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源(上图中是一个存储服务)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。
除了GC以外,有很多原因会导致进程的pause,比如需存造成的缺页故障(page falut),再比如CPU资源的竞争。即使不考虑进程pause的情况,网络延迟也仍然会造成类似的结果。
总结起来就是说,即使锁服务本身是没有问题的,而仅仅是客户端有长时间的pause或网络延迟,仍然会造成两个客户端同时访问共享资源的冲突情况发生。
1.2.3. 问题3
如下示例说明了Redlock对系统计时(timing)过分依赖,还是假设有5个Redis节点A B C D E:
- 客户端1从Redis节点A B C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户单2从Redis节点C D E成功获取了同一个资源的锁(多数节点)
- 客户端1和客户端2现在都认为自己持有了锁
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了。
好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何计时假设(timing assumption)。在异步模型中:进程可能pause任意上的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能再有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的Paxos或Raft。但显然按这个标准的话,Redlock的安全性级别是达不到的。
锁的用途可以分为以下两种:
- 为了效率(efficiency)。协调各个客户端避免做重复的工作。即使锁偶尔失效了,只是可能把某些操作多做一遍而已,不会产生其他的不良后果。比如重复发送一封同样的email。
- 为了正确性(correctness)。在任何情况下都不允许锁失效的情况发生,因为一旦发生,就可能意味着数据不一致(inconsistency),数据丢失,文件损坏,或者其他严重的问题。
因此应该根据不同的场景选择不同的锁:
- 如果是为了效率(efficiency)而使用分布式锁,允许锁的偶尔失效,那么使用单Redis节点的锁方案就足够了,简单而且效率高。Redlock而是一个过重的实现
- 如果是为了正确性(correctness)在很严肃的场合使用分布式锁,那么不要使用Redlock。它不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分(对于timing)。
1.3. 基于Zookeeper的分布式锁更安全吗?
很多人都认为,如果你想构建一个更安全的分布式锁,那么应该使用Zookeeper,而不是Redis。那么基于Zookeeper的分布式锁能提供绝对的安全吗?
下面是一个基于Zookeeper构建分布式锁的描述(当然这不是唯一的方式):
- 客户端尝试创建一个znode节点,比如/lock。那么第一个客户端就创建成功了,相当于拿到了锁;而其他的客户端会创建失败(znode已存在),获取锁失败。
- 持有锁的客户端访问共享资源完成后,将znode删掉,这样其他客户端接下来就能获取锁了。
- znode应该被创建成ephemeral的。这是znode的一个特性,它保证如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这保证了锁一定会被释放。
看起来这个锁相当完美,没有Redlock过期时间的问题,而且能在需要的时候让锁自动释放。但仔细考虑的话,并不尽然。
ZooKeeper是怎么检测出某个客户端已经崩溃了呢?实际上,每个客户端都与ZooKeeper的某台服务器维护着一个Session,这个Session依赖定期的心跳(heartbeat)来维持。如果ZooKeeper长时间收不到客户端的心跳(这个时间称为Session的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
设想如下的执行序列:
- 客户端1创建了znode节点/lock,获得了锁
- 客户端1进入了长时间的GC pause
- 客户端1连接到ZooKeeper的Session过期了。znode节点/lock被自动删除。
- 客户端2创建了znode节点/lock,从而获得了锁
- 客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
最后,客户端1和客户端2都认为自己持有了锁,冲突了。
看起来了,用ZooKeeper实现的分布式锁也不一定就是安全的。该有的问题它还是有。但是,ZooKeeper作为一个专门为分布式应用提供方案的框架,它提供了一些非常好的特性,是Redis之类的方案所没有的。像前面提到的ephemeral类型的znode自动删除的功能就是一个例子。
还有一个很有用的特性是ZooKeeper的watch机制。这个机制可以这样来使用,比如当客户端试图创建/lock的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。客户端可以进入一种等待状态,等待当/lock节点被删除的时候,ZooKeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这样的特性Redlock就无法实现。
小结一下,基于Zookeeper的锁和基于Redis的锁相比在实现特性上有两个不同:
- 在正常情况下,客户端可以持有锁任意上时间,这可以确保它做完所有需要的资源访问操作之后再释放锁。这避免了基于Redis的锁对于有效时间(lock validity time)到底设置多长的两难问题。实际上,基于ZooKeeper的锁是依靠Session(心跳)来维持锁的持有状态的,而Redis不支持Session。
- 基于ZooKeeper的锁支持在获取锁失败后等待锁重试释放的事件。这让客户端对锁的使用更加灵活。
摘自: Redlock算法