1. goroutine
我已经在很多大公司的面试里遇到这个问题! 而且这也是一个gopher必须懂的技术点! 毕竟这是go的一大特色!
1.1. 前言
进程
进程是"程序执行的一个实例",担当分配系统资源的实体,进程创建必须分配一个完整的独立地址空间!
进程是系统资源分配的最小单位,系统由一个个进程(程序)组成,一般情况下,包括文本区域
书中: 通常进程还要包含其他资源,像打开的文件,挂起的信号,内核内部数据,处理器状态,一个或者多个具有内存映射的内存地址空间及一个或多个执行线程,当然还包括用来存放全局变量的数据段等! 实际上,进程就是正在执行的程序代码的实时结果(但程序本身不是进程),内核需要有效而又透明的挂历所有细节!
进程是抢占式的争夺CPU运行自身,而CPU单核的情况下同一时间只能执行一个进程的代码,但是多个进程的实现则是通过CPU飞快的切换不同进程,因此看上去就像多个进程在同时进行
由于进程间是隔离的,各自拥有自己的内存资源,因此相对线程比较安全,所以不同进程之间的数据只能通过 IPC(Inter-Process Communication) 进行通信共享!
线程
维基百科:线程(英语:thread)是操作系统能够进行运算调度的最小单位。
书中: 线程是进程中活动的对象,每个线程都拥有一个独立的程序计数器,进程栈和一组进程寄存器! 内核调度的对象是线程,而不是进程! Linux系统的线程实现非常特别: 它对线程和进程并不特别区分,对Linux而言,线程只不过是一种特殊的进程罢了
线程上下文一般只包含CPU上下文及其他的线程管理信息,线程创建的开销主要取决于线程堆栈的建立而分配内存的开销!这些开销并不大
线程上下文切换发生在两个线程需要同步的时候,比如进入共享数据段. 切换只CPU寄存器值需要存储,并随后用将要切换到的线程的原先存储的值重新加载到CPU寄存器中去
进程相当于一个容器,线程是运行在容器里面的,所以容器内的东西,线程是共享的,因此线程间的通信可以直接通过全局变量进行通信! 但也因此会有很多安全的问题! 另外,一个线程崩溃了,会导致整个进程也崩溃了!
协程
本处的协程指的是操作系统层面的!并不是Golang里的
协程望注意!
维基百科: 协程是计算机程序的一类组件,推广了协作式多任务的子程序,允许执行被挂起与被恢复。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程更适合于用来实现彼此熟悉的程序组件,如协作式多任务、异常处理、事件循环、迭代器、无限列表和管道。
术语: coroutine
协程可以通过yield来调用其它协程。通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的。协程的起始处是第一个入口点,在协程里,返回点之后是接下来的入口点。子例程的生命期遵循后进先出(最后一个被调用的子例程最先返回);相反,协程的生命期完全由他们的使用的需要决定。
为啥要用协程呢:
协程有助于实现:
- 状态机: 在一个子例程里实现状态机,这里状态由该过程当前的出口/入口点确定个,这可以产生可读性更高的代码
- 角色模型:并行的角色模型,例如计算机游戏。每个角色有自己的过程(这又在逻辑上分离了代码),但他们自愿地向顺序执行各角色过程的中央调度器交出控制(这是合作式多任务的一种形式)。
- 产生器:它有助于输入/输出和对数据结构的通用遍历。
进程和线程的上下文切换
进程切换分为3步:
- 切换页目录以使用新的地址空间
- 切换内核栈
- 切换硬件上下文
线程切换只需要第2,3步,因此进程的切换代价比较大
线程和协程的区别
一旦创建完线程,你就无法决定他什么时候获得时间片,什么时候会让出时间片了,你把它交给了内核!
而协程编写者可以有 一是可控的切换时机! 二是很小的切换代价!
从操作系统有没有调度权上看,协程就是因为不需要进程内核态的切换! 所以会使用它,会有这么个东西! 协程- 用户态的轻量级的线程
1.2. kernel 是如何调度线程的
在Linux中,线程是由进程来实现,线程就是轻量级进程( lightweight process ),因此在Linux中,线程的调度是按照进程的调度方式来进行调度的,也就是说线程是调度单元。Linux这样实现的线程的好处的之一是:线程调度直接使用进程调度就可以了,没必要再搞一个进程内的线程调度器。
在Linux中,调度器是基于线程的调度策略(scheduling policy)和静态调度优先级(static scheduling priority)来决定那个线程来运行。
对于下面三种调度策略SCHED_OTHER, SCHED_IDLE, SCHED_BATCH,其调度优先级sched_priority是不起作用的,即可以看成其调度优先级为0;调度策略SCHED_FIFO和SCHED_RR是实时策略,他们的调度值范围是1到99,数值越大优先级越高,另外实时调度策略的线程总是比前面三种通常的调度策略优先级更高。
通常,调度器会为每个可能的调度优先级(sched_priority value)维护一个可运行的线程列表,并且是以最高静态优先级列表头部的线程作为下次调度的线程。所有的调度都是抢占式的:如果一个具有更高静态优先级的线程转换为可以运行了,那么当前运行的线程会被强制进入其等待的队列中。下面介绍几种常见的调度策略:
SCHED_OTHER: 该策略是是默认的Linux分时调度(time-sharing scheduling)策略,它是Linux线程默认的调度策略。SCHED_OTHER策略的静态优先级总是为0,对于该策略列表上的线程,调度器是基于动态优先级(dynamic priority)来调度的,动态优先级是跟nice中相关(nice值可以由接口nice, setpriority,sched_setattr来设置),该值会随着线程的运行时间而动态改变,以确保所有具有SCHED_OTHER策略的线程公平运行。在Linux上,nice值的范围是-20到+19,默认值为0;nice值越大则优先级越低,相比高nice值(低优先级)的进程,低nice值(高优先级)的进程可以获得更多的处理器时间。使用命令ps -el查看系统的进程列表,其中NI列就是进程对应的nice值;使用top命令,看到的NI列也是nice值。运行命令的时候可用nice –n xx cmd来调整cmd任务的nice值,xx的范围是-20~19之间。
SCHED_FIFO: 先入先出调度策略(First in-first out scheduling)。该策略简单的说就是一旦线程占用cpu则一直运行,一直运行直到有更高优先级任务到达或自己放弃。
SCHED_RR: 时间片轮转调度(Round-robin scheduling)。该策略是SCHED_FIFO基础上改进来的,他给每个线程增加了一个时间片限制,当时间片用完后,系统将把该线程置于队列末尾。放在队列尾保证了所有具有相同优先级的RR任务的调度公平。使用top命令,如果PR列的值为RT,则说明该进程采用的是实时策略,即调度策略是SCHED_FIFO或者为SCHED_RR,而对于非实时调度策略(比如SCHED_OTHER)的进程,该列的值是NI+20,以供Linux内核使用。
1.3. Golang的goroutine
1.3.1. Go特性
Go语言的诞生就是为了支持高并发,有2个支持高并发的模型,CSP和Actor, 教育Occam和Erlang都选用了CSP,并且效果不错,Go也选了CSP! 但与前者不同的是,Go把channel当做头等公民
CSP和Actor 不知道是什么的,请移步 CSP模型
Go为了提供更容易使用的并发方法,使用了goroutine和channel,goroutine来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被runtime调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
Go中,协程被称为goroutine(Rob Pike说goroutine不是协程,因为他们并不完全相同),它非常轻量,一个goroutine只占几KB,并且这几KB就足够goroutine运行完,这就能在有限的内存空间内支持大量goroutine,支持了更多的并发。虽然一个goroutine的栈只占几KB,但实际是可伸缩的,如果需要更多内容,runtime会自动为goroutine分配。
“一个Goroutine是一个与其他goroutines 并发运行在同一地址空间的Go函数或方法。一个运行的程序由一个或更多个goroutine组成。它与线程、协程、进程等不同。它是一个goroutine。”
1.4. goroutine 和 thread 的区别
面试必考
goroutine白话: Goroutine 可以看作对 thread 加的一层抽象,它更轻量级,可以单独执行。因为有了这层抽象,Gopher 不会直接面对 thread,我们只会看到代码里满天飞的 goroutine。操作系统却相反,管你什么 goroutine,我才没空理会。我安心地执行线程就可以了,线程才是我调度的基本单位。
那 goroutine 与 thread的区别呢?
内存占用
创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
对于一个用 Go 构建的 HTTP Server 而言,对到来的每个请求,创建一个 goroutine 用来处理是非常轻松的一件事。而如果用一个使用线程作为并发原语的语言构建的服务,例如 Java 来说,每个请求对应一个线程则太浪费资源了,很快就会出 OOM 错误(OutOfMermoryError)。
创建和销毀
Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。
Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
1.5. Go语言的调度器
提到“调度”,我们首先想到的就是操作系统对进程、线程的调度。操作系统调度器会将系统中的多个线程按照一定算法调度到物理CPU上去运行。传统的编程语言比如C、C++等的并发实现实际上就是基于操作系统调度的,即程序负责创建线程(一般通过pthread等lib调用实现),操作系统负责调度。这种传统支持并发的方式有诸多不足:
- 复杂
- 创建容易,退出难:做过C/C++ Programming的童鞋都知道,创建一个thread(比如利用pthread)虽然参数也不少,但好歹可以接受。但一旦涉及到thread的退出,就要考虑thread是detached,还是需要parent thread去join?是否需要在thread中设置cancel point,以保证join时能顺利退出?
- 并发单元间通信困难,易错:多个thread之间的通信虽然有多种机制可选,但用起来是相当复杂;并且一旦涉及到shared memory,就会用到各种lock,死锁便成为家常便饭;
- thread stack size的设定:是使用默认的,还是设置的大一些,或者小一些呢?
- 难于scaling
- 一个thread的代价已经比进程小了很多了,但我们依然不能大量创建thread,因为除了每个thread占用的资源不小之外,操作系统调度切换thread的代价也不小;
- 对于很多网络服务程序,由于不能大量创建thread,就要在少量thread里做网络多路复用,即:使用epoll/kqueue/IoCompletionPort这套机制,即便有libevent/libev这样的第三方库帮忙,写起这样的程序也是很不易的,存在大量callback,给程序员带来不小的心智负担。
为此,Go采用了用户层轻量级thread或者说是类coroutine的概念来解决这些问题,Go将之称为”goroutine“。goroutine占用的资源非常小(Go 1.4将每个goroutine stack的size默认设置为2k),goroutine调度的切换也不用陷入(trap)操作系统内核层完成,代价很低。因此,一个Go程序中可以创建成千上万个并发的goroutine。所有的Go代码都在goroutine中执行,哪怕是go的runtime也不例外。将这些goroutines按照一定算法放到“CPU”上执行的程序就称为goroutine调度器或goroutine scheduler。
不过,一个Go程序对于操作系统来说只是一个用户层程序,对于操作系统而言,它的眼中只有thread,它甚至不知道有什么叫Goroutine的东西的存在。goroutine的调度全要靠Go自己完成,实现Go程序内goroutine之间“公平”的竞争“CPU”资源,这个任务就落到了Go runtime头上,要知道在一个Go程序中,除了用户代码,剩下的就是go runtime了。
于是Goroutine的调度问题就演变为go runtime如何将程序内的众多goroutine按照一定算法调度到“CPU”资源上运行了。在操作系统层面,Thread竞争的“CPU”资源是真实的物理CPU,但在Go程序层面,各个Goroutine要竞争的”CPU”资源是什么呢?Go程序是用户层程序,它本身整体是运行在一个或多个操作系统线程上的,因此goroutine们要竞争的所谓“CPU”资源就是操作系统线程。这样Go scheduler的任务就明确了:将goroutines按照一定算法放到不同的操作系统线程中去执行。这种在语言层面自带调度器的,我们称之为原生支持并发。
1.5.1. 并发模型的实现原理
再说调度器之前,先说下几个线程模型的实现,方便理解!
从线程讲起,无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。
我们现在的计算机语言,可以狭义的认为是一种“软件”,它们中所谓的“线程”,往往是用户态的线程,和操作系统本身内核态的线程(简称KSE),还是有区别的。
线程模型的实现,可以分为以下几种方式:
用户级线程模型
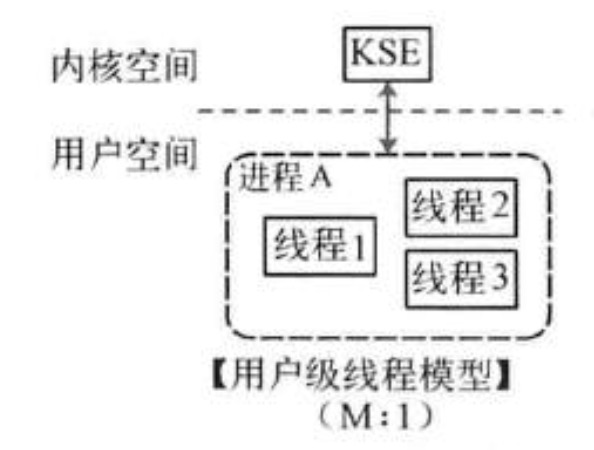
多个用户态的线程对应着一个内核线程,程序线程的创建、终止、切换或者同步等线程工作必须自身来完成。
内核级线程模型
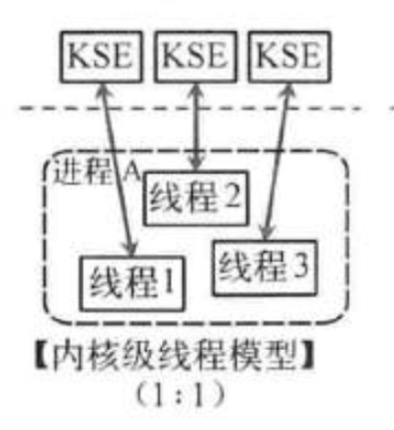
这种模型直接调用操作系统的内核线程,所有线程的创建、终止、切换、同步等操作,都由内核来完成。C++就是这种。
两级线程模型
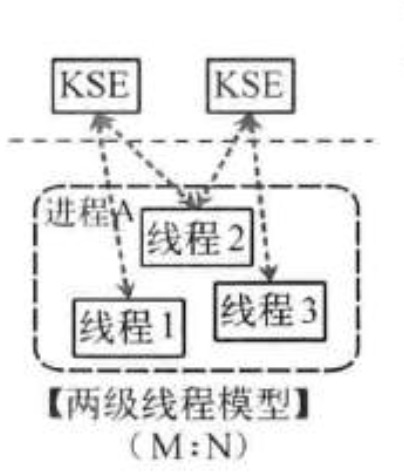
这种模型是介于用户级线程模型和内核级线程模型之间的一种线程模型。这种模型的实现非常复杂,和内核级线程模型类似,一个进程中可以对应多个内核级线程,但是进程中的线程不和内核线程一一对应;这种线程模型会先创建多个内核级线程,然后用自身的用户级线程去对应创建的多个内核级线程,自身的用户级线程需要本身程序去调度,内核级的线程交给操作系统内核去调度。
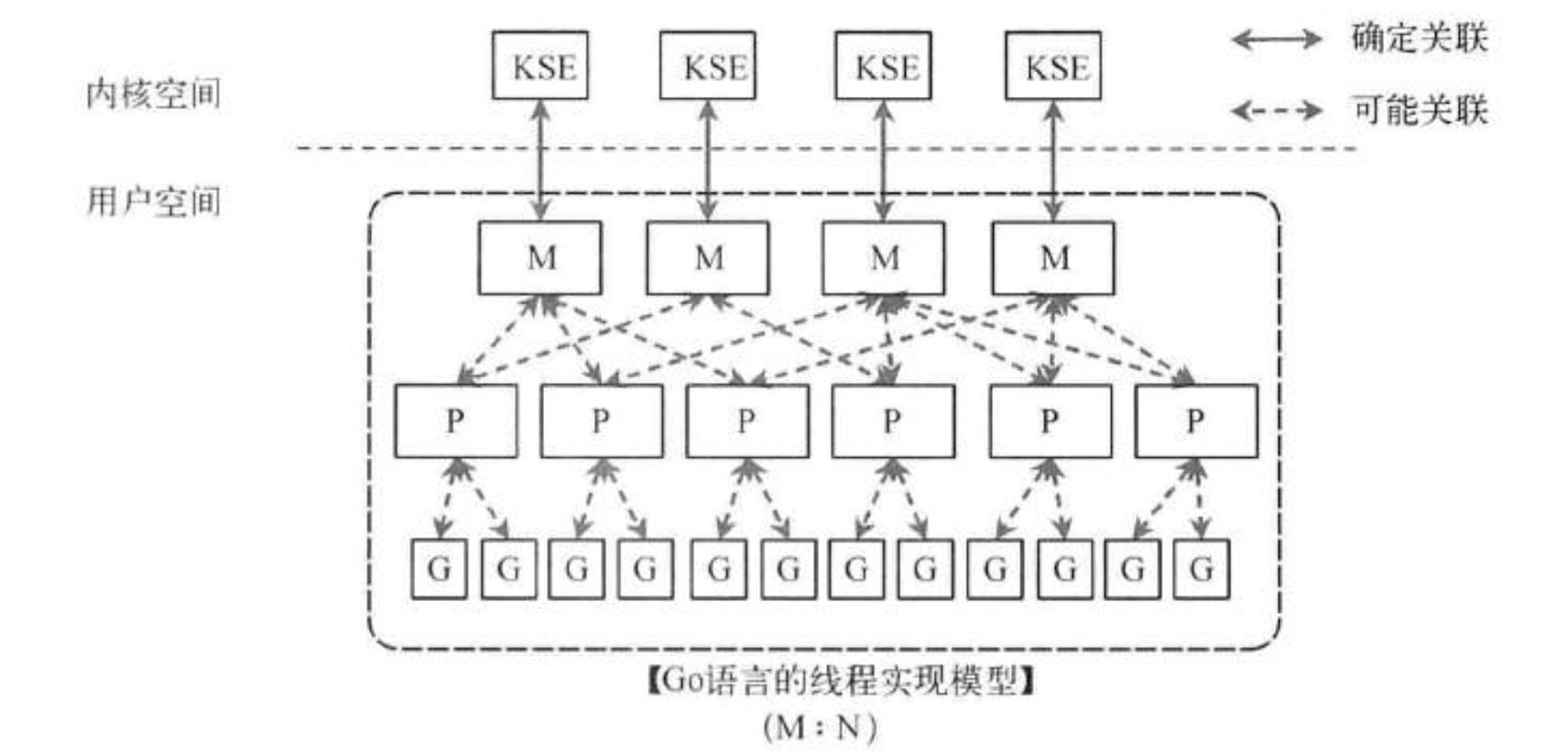
Go语言的线程模型就是一种特殊的两级线程模型。
下面讲到调度器的时候,会有更宏观的图来解释!
1.5.2. 老调度器 G-M模型
2012年3月28日,Go 1.0正式发布。在这个版本中,Go team实现了一个简单的调度器。在这个调度器中,每个goroutine对应于runtime中的一个抽象结构:G,而os thread作为“物理CPU”的存在而被抽象为一个结构:M(machine)。这个结构虽然简单,但是却存在着许多问题。前Intel blackbelt工程师、现Google工程师Dmitry Vyukov在其《Scalable Go Scheduler Design》一文中指出了G-M模型的一个重要不足: 限制了Go并发程序的伸缩性,尤其是对那些有高吞吐或并行计算需求的服务程序。主要体现在如下几个方面:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有goroutine相关操作,比如:创建、重新调度等都要上锁;
- goroutine传递问题:M经常在M之间传递”可运行”的goroutine,这导致调度延迟增大以及额外的性能损耗;
- 每个M做内存缓存,导致内存占用过高,数据局部性较差;
- 由于syscall调用而形成的剧烈的worker thread阻塞和解除阻塞,导致额外的性能损耗。
老调度器大概是下面这个样子:
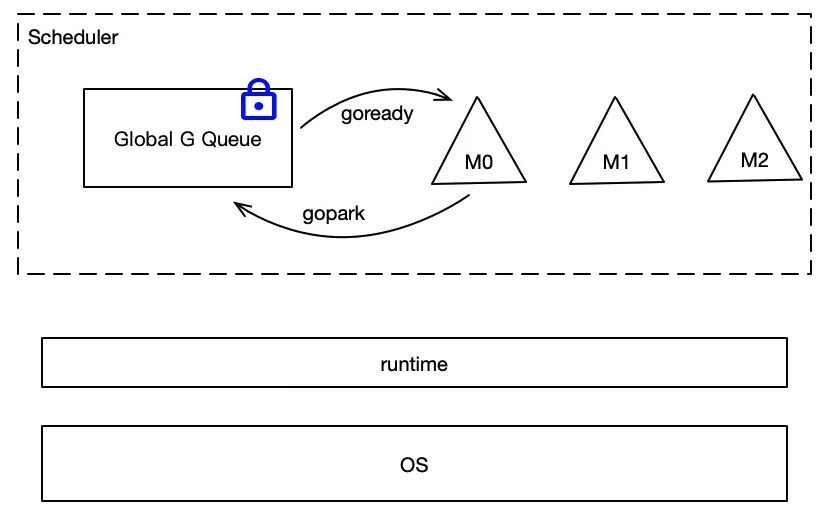
最下面是操作系统,中间是runtime,runtime在Go中很重要,许多程序运行时的工作都由runtime完成,调度器就是runtime的一部分,虚线圈出来的为调度器,它有两个重要组成:
- M,代表线程,它要运行goroutine。
- Global G Queue,是全局goroutine队列,所有的goroutine都保存在这个队列中,goroutine用G进行代表。
M想要执行、放回G都必须访问全局G队列,并且M有多个,即多线程访问同一资源需要加锁进行保证互斥/同步,所以全局G队列是有互斥锁进行保护的。
1.5.3. 新调度器 G-P-M模型
于是Dmitry Vyukov亲自操刀改进Go scheduler,在Go 1.1中实现了G-P-M调度模型和work stealing算法,这个模型一直沿用至今:
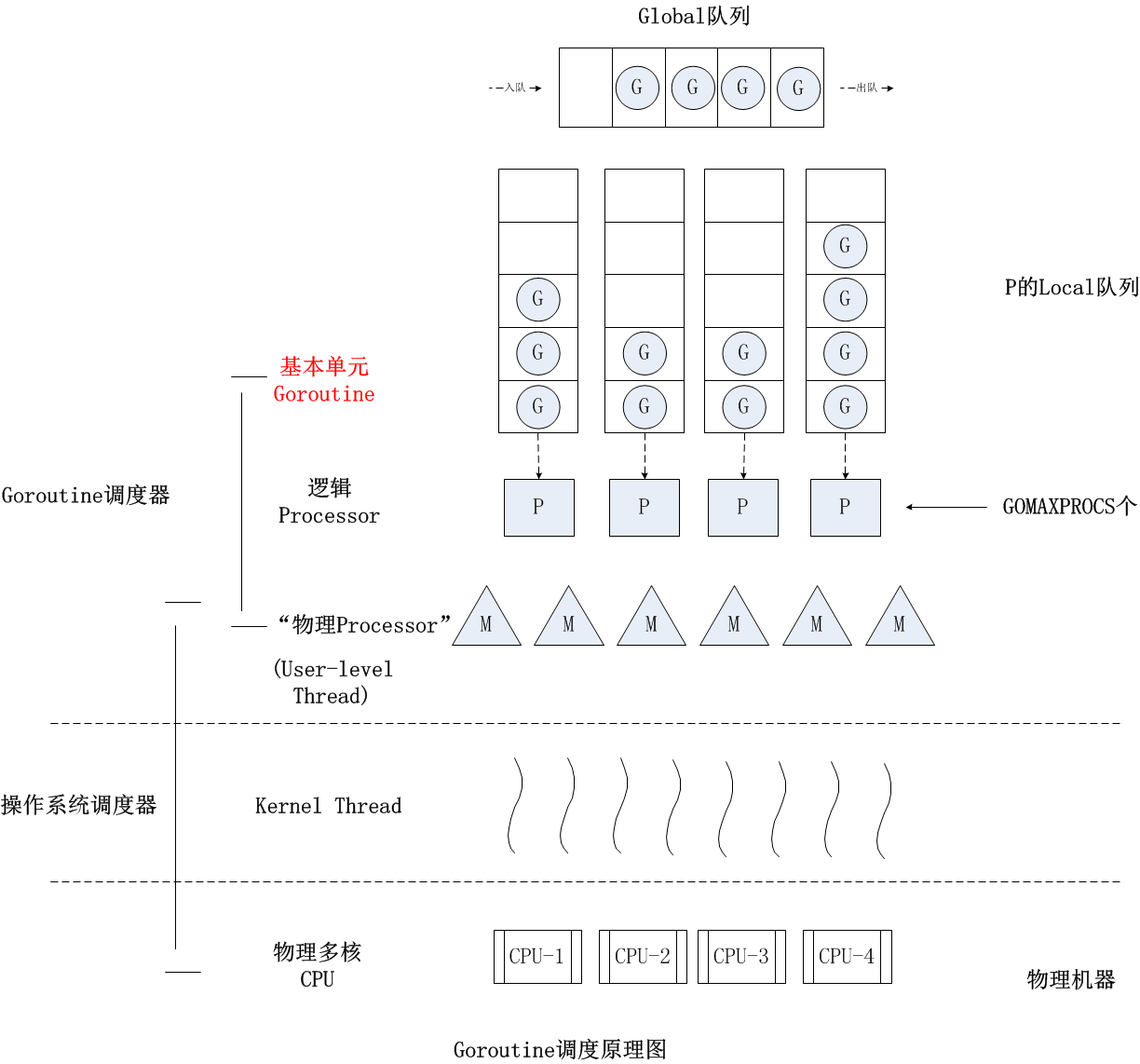
有名人曾说过:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决”,我觉得Dmitry Vyukov的G-P-M模型恰是这一理论的践行者。Dmitry Vyukov通过向G-M模型中增加了一个P,实现了Go scheduler的scalable。
P是一个“逻辑Proccessor”,每个G要想真正运行起来,首先需要被分配一个P(进入到P的local runq中,这里暂忽略global runq那个环节)。对于G来说,P就是运行它的“CPU”,可以说:G的眼里只有P。但从Go scheduler视角来看,真正的“CPU”是M,只有将P和M绑定才能让P的runq中G得以真实运行起来。这样的P与M的关系,就好比Linux操作系统调度层面用户线程(user thread)与核心线程(kernel thread)的对应关系那样(N x M)。
关于G、P、M的定义,大家可以参见$GOROOT/src/runtime/runtime2.go这个源文件。这三个struct都是大块儿头,每个struct定义都包含十几个甚至二、三十个字段。像scheduler这样的核心代码向来很复杂,考虑的因素也非常多,代码“耦合”成一坨。不过从复杂的代码中,我们依然可以看出来G、P、M的各自大致用途(当然雨痕老师的源码分析功不可没),这里简要说明一下:
- G: 表示goroutine,存储了goroutine的执行stack信息、goroutine状态以及goroutine的任务函数等;另外G对象是可以重用的。
- P: 表示逻辑processor,P的数量决定了系统内最大可并行的G的数量(前提:系统的物理cpu核数>=P的数量);P的最大作用还是其拥有的各种G对象队列、链表、一些cache和状态。
- M: M代表着真正的执行计算资源。在绑定有效的p后,进入schedule循环;而schedule循环的机制大致是从各种队列、p的本地队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到m,如此反复。M并不保留G状态,这是G可以跨M调度的基础。
下面是G、P、M定义的代码片段:
//src/runtime/runtime2.go
type g struct {
stack stack // offset known to runtime/cgo
sched gobuf
goid int64
gopc uintptr // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
... ...
}
type p struct {
lock mutex
id int32
status uint32 // one of pidle/prunning/...
mcache *mcache
racectx uintptr
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// Available G's (status == Gdead)
gfree *g
gfreecnt int32
... ...
}
type m struct {
g0 *g // goroutine with scheduling stack
mstartfn func()
curg *g // current running goroutine
.... ..
}
三者宏观关系图是:
1.5.4. 调度器调度过程
看几个几个场景之前,先说明两个点,提前预习!
关于g0栈和g栈
由于m是实际执行体,m的整个代码逻辑基本上就是整个调度逻辑。类似于Linux的内核栈和用户栈,Go的m也有两类栈:一类是系统栈(或者叫调度栈),主要用于运行runtime的程序逻辑;另一类是g栈,用于运行g的程序逻辑。每个m在创建时会分配一个默认的g叫g0,g0不执行任何代码逻辑,只是用来存放m的调度栈等信息。当要执行Go runtime的一些逻辑比如创建g、新建m等,都会首先切换到g0栈然后执行,而执行g任务时,会切换到g的栈上。在调度栈和g栈上不断切换使整个调度过程复杂了不少。
关于m的spinning自旋
在Go的调度中,m一旦被创建则不会退出。在系统调用、cgocall、lockOSThread时,为了防止阻塞其他g的执行,Go会新建或者唤醒m(os线程)执行其他的g,所以可能导致m的增加。如何保证m数量不会太多,同时有足够的线程使p(cpu)不会空闲?主要的手段是通过多路复用和m的spinning。多路复用解决网络和文件io时的阻塞(与net poll类似,Go1.8.1的代码中为os.File加了poll接口),避免每次读写的系统调用消耗线程。而m的spinning的作用是尽量保证始终有m处于spinning寻找g(并不是执行g,充分利用多cpu)的同时,不会有太多m同时处于spinning(浪费cpu)。不同于一般意义的自旋,m处于自旋是指m的本地队列、全局队列、poller都没有g可运行时,m进入自旋并尝试从其他p偷取(steal)g,每当一个spinning的m获取到g后,会退出spinning并尝试唤醒新的m去spinning。所以,一旦总的spinning的m数量大于0时,就不用唤醒新的m了去spinning浪费cpu了。
goroutine状态(简化版)
| 状态 | 解释 |
|---|---|
| Waiting | 等待状态,goroutine在等待某件事的发生,例如等待网络数据,硬盘;调用操作系统API;等待内存同步访问条件ready,例如atomic,mutexes |
| Runnable | 就绪状态,只要给M我就可以运行 |
| Executing | 运行状态; goroutine在M上执行指令,这是我们想要的 |
- goroutine生命周期
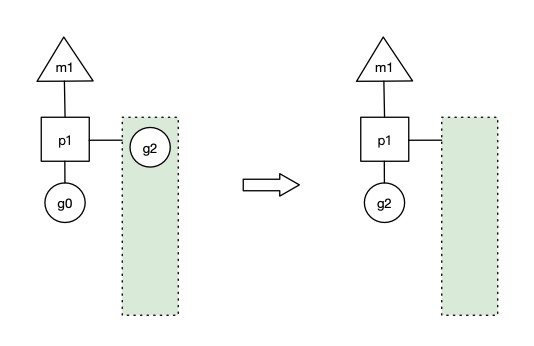
- 场景1: p1拥有g1,m1获取p1后开始运行g1,g1使用
go func()创建了g2,为了局部性g2优先加入到p1的本地队列。
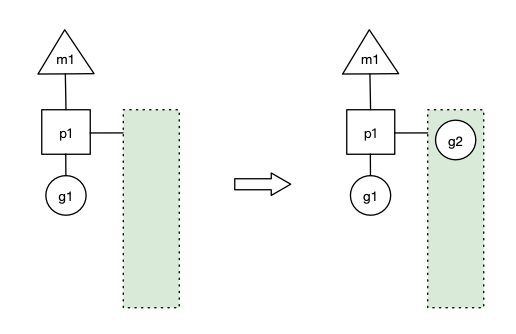
上图中三角形、正方形、圆形分别代表了M、P、G,正方形连接的绿色长方形代表了P的本地队列。
- 场景2: g1运行完成后(函数:goexit),m上运行的goroutine切换为g0(别问g0从哪来的了,往上
预习的里面看),g0负责调度时协程的切换(函数:schedule)。从p1的本地队列取g2,从g0切换到g2,并开始运行g2(函数:execute)。实现了线程m1的复用。
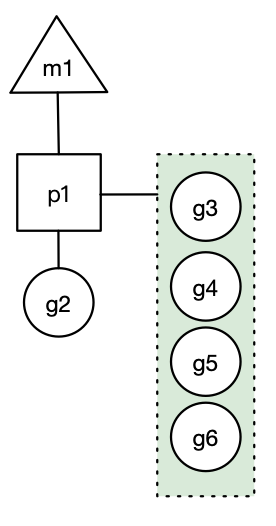
- 场景3: 假设每个p的本地队列只能存4个g。g2要创建了6个g,前4个g(g3, g4, g5, g6)已经加入p1的本地队列,p1本地队列满了。 怎么处理呢,看场景4
- 场景4: g2在创建g7的时候,发现p1的本地队列已满,需要执行负载均衡,把p1中本地队列中前一半的g,还有新创建的g转移到全局队列(实现中并不一定是新的g,如果g是g2之后就执行的,会被保存在本地队列,利用某个老的g替换新g加入全局队列),这些g被转移到全局队列时,会被打乱顺序。所以g3,g4,g7被转移到全局队列。上面说创建6个,现在还有一个g8需要创建,放在哪呢?看场景5
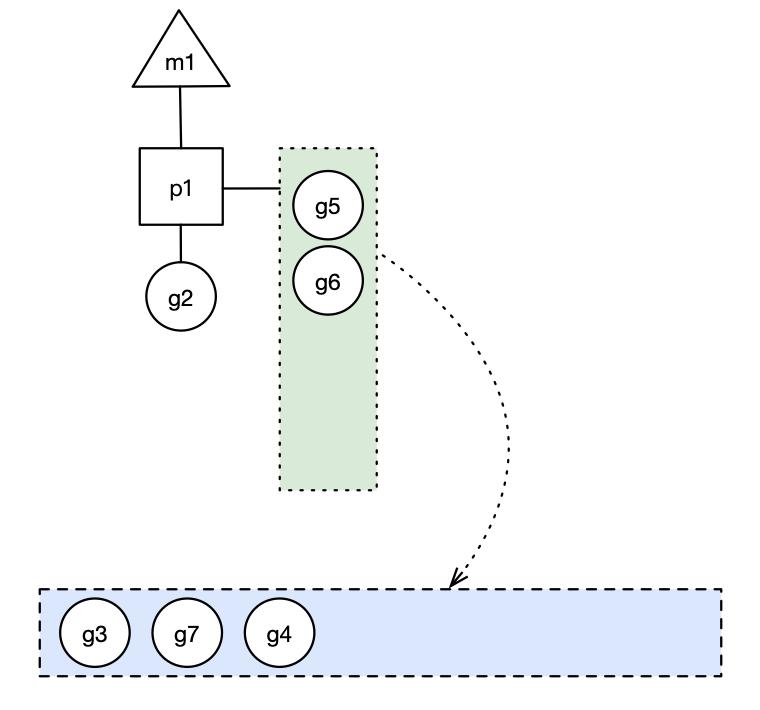
上图蓝色长方形代表全局队列。
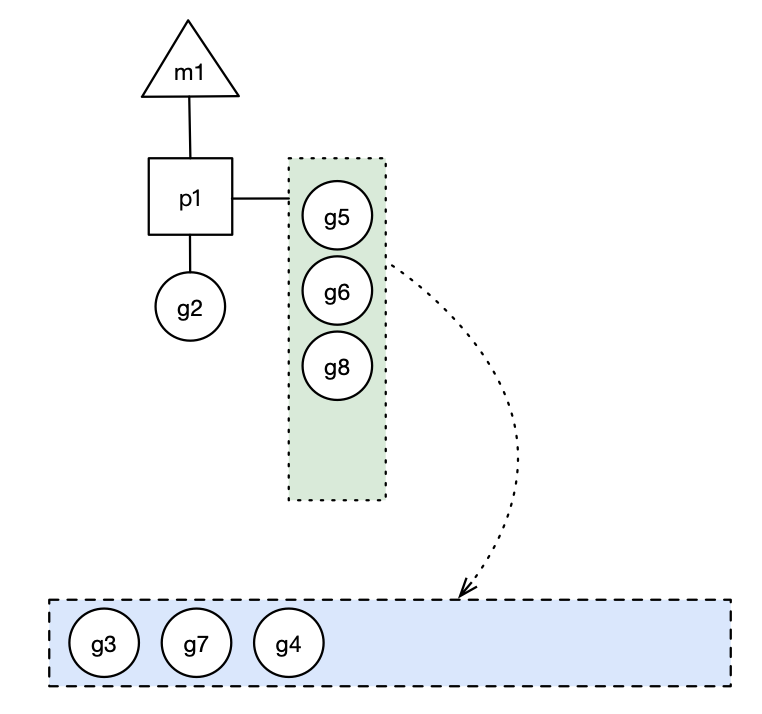
- 场景5: g2创建g8时,p1的本地队列未满,所以g8会被加入到p1的本地队列。
- 场景6: 在创建g时,运行的g会尝试唤醒其他空闲的p和m执行。假定g2唤醒了m2,m2绑定了p2,并运行g0,但p2本地队列没有g,m2此时为自旋线程(没有G但为运行状态的线程,不断寻找g,后续场景会有介绍)。
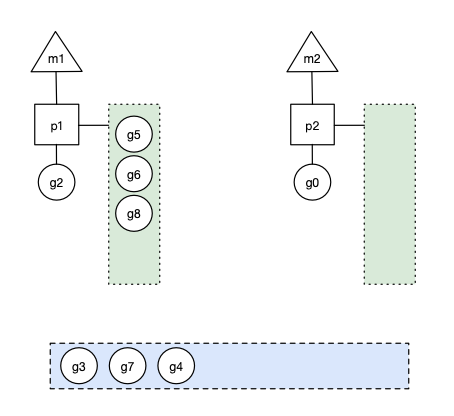
场景7: m2尝试从全局队列(GQ)取一批g放到p2的本地队列(函数:findrunnable)。m2从全局队列取的g数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS + 1, len(GQ/2))
公式的含义是,至少从全局队列取1个g,但每次不要从全局队列移动太多的g到p本地队列,给其他p留点。这是从全局队列到P本地队列的负载均衡。
假定我们场景中一共有4个P,所以m2只从能从全局队列取1个g(即g3)移动p2本地队列,然后完成从g0到g3的切换,运行g3。
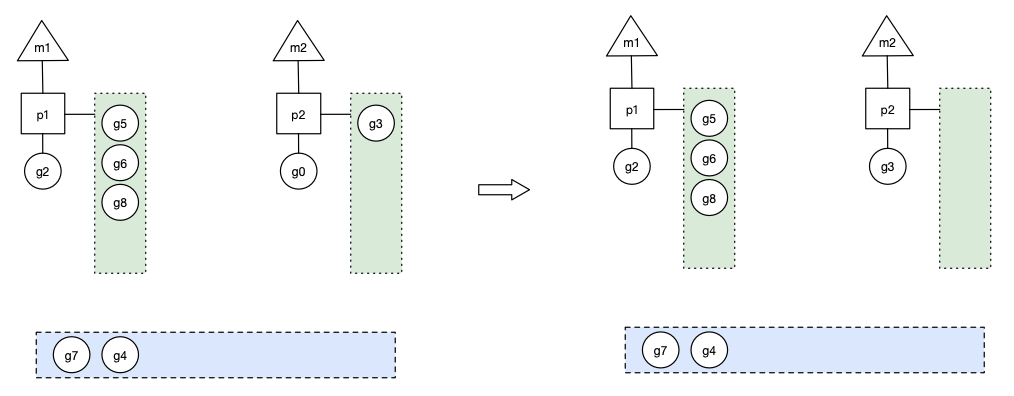
场景8: 假设g2一直在m1上运行,经过2轮后,m2已经把g7、g4也挪到了p2的本地队列并完成运行,全局队列和p2的本地队列都空了,如下图左边(原图左边本地队列的队尾漏了一个g8...)。
全局队列已经没有g,那m就要执行work stealing:从其他有g的p哪里偷取一半g过来,放到自己的P本地队列。 p2从p1的本地队列尾部取一半的g,本例中一半则只有1个g8,放到p2的本地队列,情况如下图右边
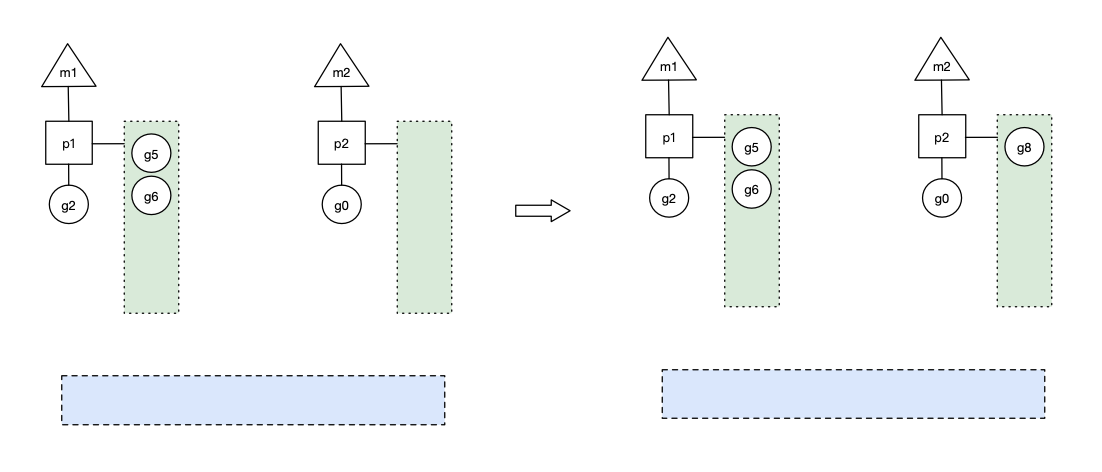
- 场景9: p1本地队列g5、g6已经被其他m偷走并运行完成,当前m1和m2分别在运行g2和g8,m3和m4没有goroutine可以运行,m3和m4处于自旋状态,它们不断寻找goroutine。为什么要让m3和m4自旋,自旋本质是在运行,线程在运行却没有执行g,就变成了浪费CPU?销毁线程不是更好吗?可以节约CPU资源。创建和销毁CPU都是浪费时间的,我们希望当有新goroutine创建时,立刻能有m运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费CPU,所以系统中最多有GOMAXPROCS个自旋的线程,多余的没事做线程会让他们休眠(见函数:notesleep())。
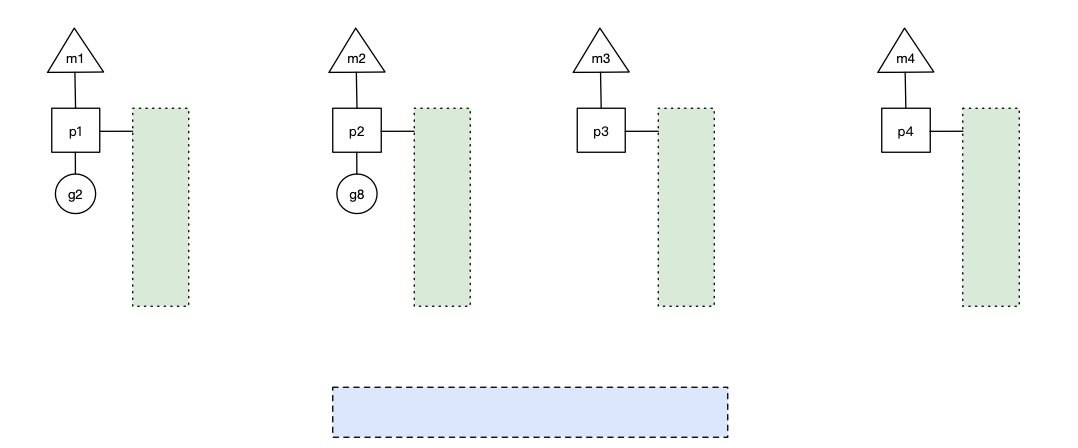
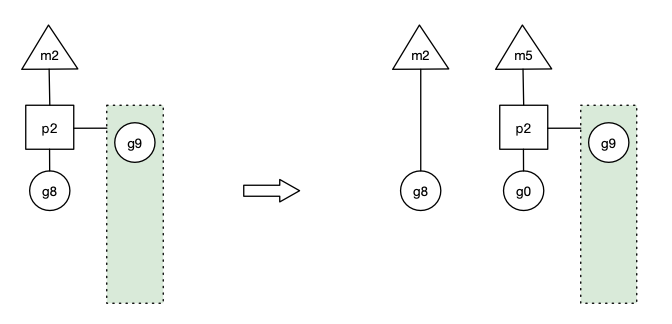
- 场景10: 假定当前除了m3和m4为自旋线程,还有m5和m6为自旋线程,g8创建了g9,g8进行了阻塞的系统调用,m2和p2立即解绑(m2继续带着g8),p2会执行以下判断:如果p2本地队列有g、全局队列有g或有空闲的m,p2都会立马唤醒1个m和它绑定,否则p2则会加入到空闲P列表,等待m来获取可用的p。本场景中,p2本地队列有g,可以和其他自旋线程m5绑定。当系统调用结束之后!g8会找有没有其他的p,比如图中,p2还在,那么就会加入到p2的本地队列! 如果没有找到,g8会被标记为 runnable!加入到Global队列
- 场景11:(无图场景)g8创建了g9,假如g8进行了非阻塞系统调用(CGO会是这种方式,见cgocall()),m2和p2会解绑,但m2会记住p,然后g8和m2进入系统调用状态。当g8和m2退出系统调用时,会尝试获取p2,如果无法获取,则获取空闲的p,如果依然没有,g8会被记为可运行状态,并加入到全局队列。
这个场景11,应该就是 场景10的另外一种情况, 场景10是 同步(阻塞调用),场景11应该是 异步(非阻塞调用!),但是我看了好几篇文章,跟上面场景11描述的有点出入!
场景11和场景10说的都是 system call (系统级调用)的情况下!
如果是 channel阻塞或者network I/O情况下, 就是场景12的情况了!!!!!!!!!!!!
场景11副本(其他多篇文章的情况): g8创建了g9,假如g8进行了非阻塞系统调用,m2不会阻塞! g8的异步请求会被 "代理人"
network poller接手!g8也会绑定到这个 network poller 上,移动到网络轮询器队列中,与此同时,因为m2没有阻塞,他能继续执行p2里本地队列的其他G! 等g8由网络轮询器完成后! g8就会被移回到p2的本地队列中!场景12: (无图场景)g会被放置到某个wait队列中,而m会尝试执行下一个runnable的个,如果此时没有runnable的g供m运行!那么m将解绑P,并进入sleep状态。当I/O available或channel操作完成,在wait队列中的g会被唤醒,标记为runnable,放入到某P的队列中,绑定一个m继续执行。
场景13:(无图场景)Go调度在go1.12实现了抢占,应该更精确的称为请求式抢占,那是因为go调度器的抢占和OS的线程抢占比起来很柔和,不暴力,不会说线程时间片到了,或者更高优先级的任务到了,执行抢占调度。go的抢占调度柔和到只给goroutine发送1个抢占请求,至于goroutine何时停下来,那就管不到了。抢占请求需要满足2个条件中的1个:1)G进行系统调用超过20us,2)G运行超过10ms。调度器在启动的时候会启动一个单独的线程sysmon,它负责所有的监控工作,其中1项就是抢占,发现满足抢占条件的G时,就发出抢占请求。
简单说下时间片的概念: 在操作系统中,线程执行都会在一个固定的时间片来执行命令,一般都是10ms,如果在10ms内执行完了,那么让出cpu,如果没有执行完,一样要让出cpu,然后当前线程会中断挂起等待下一个时间片! 当然,具体还得看操作系统内部的调度算法!
看完上面的场景之后! 再来看 雨痕 大佬的这个图! 会好理解很多!

举个例子
package main
import "fmt"
// main.main
func main() {
fmt.Println("Hello scheduler")
}
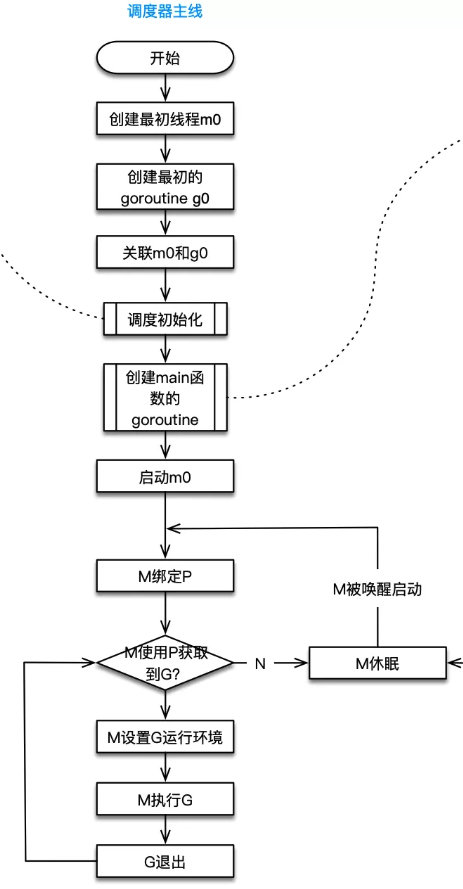
runtime创建最初的线程m0和goroutine g0,并把2者关联。
调度器初始化:初始化m0、栈、垃圾回收,以及创建和初始化由GOMAXPROCS个P构成的P列表。
示例代码中的main函数是main.main,runtime中也有1个main函数——runtime.main,代码经过编译后,runtime.main会调用main.main,程序启动时会为runtime.main创建goroutine,称它为main goroutine吧,然后把main goroutine加入到P的本地队列。
启动m0,m0已经绑定了P,会从P的本地队列获取G,获取到main goroutine。
G拥有栈,M根据G中的栈信息和调度信息设置运行环境
M运行G
G退出,再次回到M获取可运行的G,这样重复下去,直到main.main退出,runtime.main执行Defer和Panic处理,或调用runtime.exit退出程序。
调度器的生命周期几乎占满了一个Go程序的一生,runtime.main的goroutine执行之前都是为调度器做准备工作,runtime.main的goroutine运行,才是调度器的真正开始,直到runtime.main结束而结束。
1.6. 调度器的两大思想和两小策略
- 两大思想
- 复用线程:协程本身就是运行在一组线程之上,不需要频繁的创建、销毁线程,而是对线程的复用。在调度器中复用线程还有2个体现:1)work stealing,当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程。2)hand off,当本线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行。
- 利用并行:GOMAXPROCS设置P的数量,当GOMAXPROCS大于1时,就最多有GOMAXPROCS个线程处于运行状态,这些线程可能分布在多个CPU核上同时运行,使得并发利用并行。另外,GOMAXPROCS也限制了并发的程度,比如GOMAXPROCS = 核数/2,则最多利用了一半的CPU核进行并行。
- 两小策略
- 抢占:在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在Go中,一个goroutine最多占用CPU 10ms,防止其他goroutine被饿死,这就是goroutine不同于coroutine的一个地方。
- 全局G队列:在新的调度器中依然有全局G队列,但功能已经被弱化了,当M执行work stealing从其他P偷不到G时,它可以从全局G队列获取G。
上面提到并行了,关于并发和并行再说一下:Go创始人Rob Pike一直在强调Go是并发,不是并行,因为Go做的是在一段时间内完成几十万、甚至几百万的工作,而不是同一时间同时在做大量的工作。并发可以利用并行提高效率,调度器是有并行设计的。
1.7. goroutine调度时机
| 情形 | 说明 |
|---|---|
使用关键字go |
go创建一个新的 goroutine, Go scheduler会考虑调度 |
| GC | 由于进行GC的goroutine也需要在M上运行,因此肯定会发生调度,当然,Go scheduler还会做很多其他的调度,例如调度不涉及堆访问的goroutine来运行!GC不管栈上的内存,只会回收堆上的内存 |
| 系统调用 | 当goroutine进行系统调用时,会阻塞M,所有它会被调度走,同时一个新的goroutine会被调度上来 |
| 内存同步访问 | atomic,mutex,channel操作等会使goroutine阻塞,因此会被调度走,等条件满足后(例如其他的goroutine解锁了)还会被调度上来继续运行 |
1.8. 上线文切换
简单理解为当时的环境即可,环境可以包括当时程序状态以及变量状态。例如线程切换的时候在内核会发生上下文切换,这里的上下文就包括了当时寄存器的值,把寄存器的值保存起来,等下次该线程又得到cpu时间的时候再恢复寄存器的值,这样线程才能正确运行。
对于代码中某个值说,上下文是指这个值所在的局部(全局)作用域对象。相对于进程而言,上下文就是进程执行时的环境,具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存(堆栈)信息等。
1.9. 线程清理
Goroutine被调度执行必须保证P/M进行绑定,所以线程清理只需要将P释放就可以实现线程的清理。什么时候P会释放,保证其它G可以被执行。P被释放主要有两种情况。
主动释放:最典型的例子是,当执行G任务时有系统调用,当发生系统调用时M会处于Block状态。调度器会设置一个超时时间,当超时时会将P释放。
被动释放:如果发生系统调用,有一个专门监控程序,进行扫描当前处于阻塞的P/M组合。当超过系统程序设置的超时时间,会自动将P资源抢走。去执行队列的其它G任务。
1.10. 非阻塞IO与IO多路复用
现在我们知道协程的创建和上线文切换都非常“轻”,但是在进行带阻塞系统调用时执行体M会被阻塞,这就需要创建新的系统资源,而在高并发的web场景下如果使用阻塞的IO调用,网络IO大概率阻塞较长的时间,导致我们还是要创建大量的系统线程,所以Go需要尽量使用非阻塞的系统调用,虽然Go的标准库提供的是同步阻塞的IO模型,但底层其实是使用内核提供的非阻塞的IO模型。当Goroutine进行IO操作而数据未就绪时,syscall返回error,当前执行的Goroutine被置为阻塞态而M并没有被阻塞,P就可以继续使用当前执行体M继续执行下一个G,这样P就不需要再跑到别的M,从而也就不会去创建新的M。
当然只有非阻塞IO还不够,Go抽象了netpoller对象来进行IO多路复用,在linux下通过epoll来实现IO多路复用。当G由于IO未就绪而被置为阻塞态时,netpoller将对应的文件描述符注册到epoll实例中进行epoll_wait,就绪的文件描述符回调通知给阻塞的G,G更新为就绪状态等待调度继续执行,这种实现使得Golang在进行高并发的网络通信时变得非常强大,相比于php-fpm的多进程模型,Golang Http Server使用很少的线程资源运行非常多的Goroutine,而且尽可能的让每一个线程都忙碌起来,而不是阻塞在IO调用上,提高了CPU的利用率。
1.11. scheduler 的陷阱
由于 Go 语言是协作式的调度,不会像线程那样,在时间片用完后,由 CPU 中断任务强行将其调度走。对于 Go 语言中运行时间过长的 goroutine,Go scheduler 有一个后台线程在持续监控,一旦发现 goroutine 运行超过 10 ms,会设置 goroutine 的“抢占标志位”,之后调度器会处理。但是设置标志位的时机只有在函数“序言”部分,对于没有函数调用的就没有办法了。
Golang implements a co-operative partially preemptive scheduler.
所以在某些极端情况下,会掉进一些陷阱。下面这个例子来自参考资料【scheduler 的陷阱】。
func main() {
var x int
threads := runtime.GOMAXPROCS(0)
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}
运行结果是:在死循环里出不来,不会输出最后的那条打印语句。
为什么?上面的例子会启动和机器的 CPU 核心数相等的 goroutine,每个 goroutine 都会执行一个无限循环。
创建完这些 goroutines 后,main 函数里执行一条 time.Sleep(time.Second) 语句。Go scheduler 看到这条语句后,简直高兴坏了,要来活了。这是调度的好时机啊,于是主 goroutine 被调度走。先前创建的 threads 个 goroutines,刚好“一个萝卜一个坑”,把 M 和 P 都占满了。
在这些 goroutine 内部,又没有调用一些诸如 channel, time.sleep 这些会引发调度器工作的事情。麻烦了,只能任由这些无限循环执行下去了。
解决的办法也有,把 threads 减小 1:
func main() {
var x int
threads := runtime.GOMAXPROCS(0) - 1
for i := 0; i < threads; i++ {
go func() {
for { x++ }
}()
}
time.Sleep(time.Second)
fmt.Println("x =", x)
}
运行结果:
x = 0
不难理解了吧,主 goroutine 休眠一秒后,被 go schduler 重新唤醒,调度到 M 上继续执行,打印一行语句后,退出。主 goroutine 退出后,其他所有的 goroutine 都必须跟着退出。所谓“覆巢之下 焉有完卵”,一损俱损。
至于为什么最后打印出的 x 为 0,之前的文章《曹大谈内存重排》里有讲到过,这里不再深究了。
还有一种解决办法是在 for 循环里加一句:
go func() {
time.Sleep(time.Second)
for { x++ }
}()
同样可以让 main goroutine 有机会调度执行。
本文参考:
进程、线程、轻量级进程、协程和go中的Goroutine 那些事儿